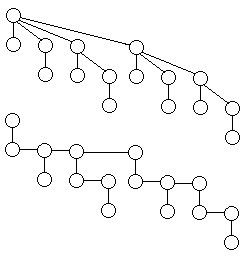
有一个女人的男人很幸福。事实上,这是片面的。应该说,有不止一个女人的男人更幸福。但是,这样会坏了我的人品,而且被女的知道了也不好。两个耍得好的女人话很多,秘密在女人中传得很快。于是,我打算不同时和两个耍得好的女的耍朋友。后来我意识到,这样也不行。女人太无敌了,即使A与B耍得好,B与C耍得好,A和C的消息也是互通的。哪怕只有一个朋友关系也能把两群人联系在一起。我不得不改变策略,使得我的女朋友之间没有任何渠道传递信息。也就是说,在上面的A、B、C三个人中,虽然A和C没有直接的联系,但我也不能同时和A、C耍。不久后,我想知道,某两个女人是否可以通过某条“朋友链”传递信息。这就是所谓的等价关系——基本上算是判断一个无向图的连通性。就像很多个集合,每次选两个并成一个,而且我们随时想知道某两个元素经过前面的合并后是否在同一个集合内。怎么办呢?后来有一天,我发现那些小女生喜欢玩些认亲戚的游戏,什么谁是谁妈,谁是谁姐,谁是谁女儿之类的(不知道为什么这些疯女人喜欢搞这些)。我突然恍然大悟,我的问题可以用树结构来完成。亲戚的亲戚还是亲戚,但有一点总相同:所有亲戚的始祖总是一样的。始祖一样的都是一伙的。因此,把两个集合并在一起,只要让其中一个集合的根成为另一个集合中的某个元素的一个儿子就行了,这种家谱关系的改变将使前面的集合中所有的元素拥有和后面那个集合一样的鼻祖,而这将成为这些元素的“标志”。这个想法的灵感是来自女人世界的,因此女人还是有一定的作用。
这就叫并查集,又叫不相交集。它可以合并两个集合并且查询两个元素是否在同一集合。我们有一个很有效的剪枝:递归时顺便把路上经过的祖祖辈辈全部变成根的儿子。这样的程序只用2行来解决。function find_set(x:integer):integer;
begin
if x<>p[x] then p[x]:=find_set(p[x]);
exit(p[x]);
end;
p[x]表示元素x的父亲的位置。一开始,p[x]都等于x自己,表示自己一个人是一个集合。函数find_set(x)将返回x所在集合(一棵树)的根。
并查集还有些其它的剪枝和一些很复杂的效率分析问题,这里不多说了。
写到这里,《数据结构与算法分析》中的几个大块内容算是说清楚了。由于本文的叙述调整了原书各章节的顺序且至此还没有涉及书里的一些小问题,因此这里想把遗漏下的一些小东西提一下。
有一些树结构可能要求同时满足多个要求。比如一个简单的问题:如果要求构造一个堆使得既能查找最小元素又能查找最大元素怎么办?这时,我们可以用一个特殊的方法来实现:树的单数层满足一种性质,树的双数层满足另一种性质。我们用一个叫做最小-最大堆的东西来实现前面说的问题。这个堆的双数层的数据小于它爸大于它爸的爸,单数层的数据反过来,大于它爸小于它爸的爸。用类似的方法,我们还可以设计一个二叉查找树,使得它能够支持含有2种不同类型元素的数据。在单数层按其中一种操作,在双数层按另一种操作,这样可以方便的查找同时位于两个不同类元素的指定区间内的数据。这种二叉查找树叫做2-d树。扩展2-d 树,我们可以得到k-d树。这些数据结构的具体实现方法这里不说了,书上本来也是作为一个习题介绍的。
书里的第7章花了近50页介绍并分析各种排序算法,分析得很全。其中第11节花了10页介绍外部排序。所谓外部排序,就是说怎样快速地把一个根本无法全部读入内存的大文件进行排序。很多排序之所以可行是因为它们可以随意读写任意一个指定的数。但在大文件里,我们无法实现“第1234567890个元素和第 123个元素交换位置”,更无法实现递归之类的操作,而只能像磁带一样“过一遍”,从头到尾扫一遍,由于文件太大内存不能接受,因此必须要读一截扔一截。于是,外部排序产生了。不要以为这个限制会把排序速度拖得很慢。事实上,外部排序同样突破了O(n^2)的界限。它借助了归并排序中的“合并两个已经有序的数组”的思想,因为这个操作可以边读就边做。把文件先拆成两个文件,再把每个文件处理成一段一段的等长有序序列(一段多大取决于内存能一次处理多大),然后不断从两个文件中各取一段出来合并。可以看到,每段有序序列的长度变长了,变成了2倍长。过不了几次,这个长度将变成文件的总长。注意,我们必须要让每次合并时为下次合并做好准备(就是说合并后的结果仍然要是两个分了段的文件)。一个好的方法是将合并的结果交替存在两个不同的新文件中。
第9章讲图论算法。讲了图的遍历(广搜和深搜)、AOV、AOE、Dijkstra、网络流、Prim、Kruskal和NP问题。在讲深搜时,我学到了两个新东西,用线性时间查找割点(去掉了的话图就不连通了的点)和强分支(有向图中的一个分支满足其中任两个点之间都可以互相到达)。后来发现黑书上也有,又觉得这个东西很不好说,因此这里不想说了。说到了黑书还想顺便补一句:黑书真的看不得——太多错误了。不是说LRJ怎么了,LRJ在真正的大问题上有他的思想和经验,但很多细节的概念他也是昏的,这不利于初学者接受知识。不信哪天我还要写一篇日志纠正黑书的错误。引用政治书上抨击“人性自私论”的经典语言:“从理论到实践都是错的”。
第10章讲“算法设计技巧”,大概是些贪心啊,分治啊,动规啊,回溯啊,随机化啊之类的。调度问题、Huffman树、装箱问题近似算法、最近点距分治算法、最优二叉查找树、Floyd-Warshall、跳跃表、Miller-Rabin素性测试、博弈算法等都在这章中有讲,并且讲得相当好。由于这不是本书的重点内容,这里也不说了。
第11章整章都在讲摊还分析。这是一个相当复杂的问题,是分析时间复杂度的一个有力工具。它的分析告诉我们的不是某一个操作的复杂度,而是重复执行某一个操作的平均复杂度。研究这个是很有必要的,因为我们会遇到一些“越变越慢”的退化情形和“自我保持不变”的自调整性等数据结构,单个操作并不能反映它真正的效率。
到这里,这本书的所有东西都已经介绍完了。总的来说,这本书很值得一看(虽然有些地方翻译得很差)。它的理论性很强,证明过程完整(再复杂的分析它也证明得很清楚,满足那些刨根问底的人);整本书自成一个体系,前后呼应;习题具有研究性,与课文互相补充。事实上,这些都是国外教材共有的特点。这算是我完整读过的第一本国外教材,今后我还会读一些。这几天在看《组合数学》(仍然是这个出版社出版的),看完后也打算写一下“对《组合数学》一书中部分内容的形象理解”。读一本国外教材,你会发现它与国内书籍的不同并会从中获益更多。
这篇文章就写到这里了。号称是一个5000字缩写,没想到写着写着已经超过8000字了。而且,这个