看到新词就上一下Wikipedia确实是一个好习惯。前一篇日志的那个pdf里作者提到了Gedankenexperiment(Thought experiment),上Wikipedia一查果然学到了牛B的新东西。好多物理定律其实完全是由思维实验推导出来的,难以置信仅仅是思考竟然就能得出物理世界遵从的各种法则。经典的物理思维实验有Newton大炮、Galileo斜塔实验、Schrödinger的猫猫、Maxwell的妖怪等等。还有,Turing机也是一个伟大的思维实验。

数学上的不少悖论(特别是涉及到维度和无穷的悖论)都是相当有趣的思维实验。Gabriel喇叭是y=1/x在[1,+∞)上的图象沿x轴旋转一周所形成的旋转体。这个简单的三维图形有一个奇特的性质:它的表面积无穷大,却只有有限的体积。为了证实这一点,只需注意到:
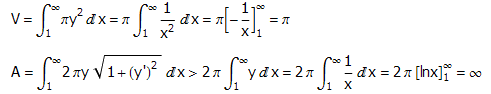
Gabriel喇叭会导出一个非常诡异的悖论:如果你想用涂料把Gabriel喇叭的表面刷一遍,你需要无穷多的涂料;然而把涂料倒进Gabriel喇叭填满整个内部空间,所需要的涂料反而是有限的。
有网友一定会问,那有没有什么二维图形,面积有限大,周长却无限长呢?答案是肯定的,Koch雪花就是这样一个经典的例子。不过,通过分形构造出来的这类图形似乎并不存在涂料悖论,因为递归到一定深度时分形图形的尺度将小于表面涂料的厚度,因此表面大小不能永无止境地算下去,涂满表面所需的涂料不再是无穷多。当考虑到涂料厚度时,原先的悖论也可以解释清楚了:填充内部空间仅仅涂满了图形的内表面,一旦考虑到涂料的厚度,它和外表面的区别就出来了。

 在数学中,比较运算是有传递性的。如果A>B,且B>C,那么一定有A>C。但现实生活中却不一定是这样。三个人两两之间进行比赛,有可能A比B要强,B比C要强,但C反过来赢了A。事实上,这种现象即使在数学中也是存在的。在一些概率事件中,类似的“大小关系”很可能并不满足传递性。
在数学中,比较运算是有传递性的。如果A>B,且B>C,那么一定有A>C。但现实生活中却不一定是这样。三个人两两之间进行比赛,有可能A比B要强,B比C要强,但C反过来赢了A。事实上,这种现象即使在数学中也是存在的。在一些概率事件中,类似的“大小关系”很可能并不满足传递性。