看守打算和 A 、 B 两名囚犯做一个游戏。首先,看守从一副牌中取出大小王,将剩余的 52 张牌洗好,并在桌子上从左至右地把它们摆成一排,每张牌都是正面朝上。然后,看守让囚犯 A 来到桌前,允许囚犯 A 观察牌面,并交换其中两张牌的位置。接着,看守将囚犯 A 关回牢房,把所有牌全都翻到背面朝上(但位置不变),让囚犯 B 来到桌前。看守随便报出一张牌的花色和点数(比如“梅花 3”),要求囚犯 B 找出这张牌。囚犯 B 每次可以翻开任意一张尚未翻开的牌,但一共只有 26 次机会。如果囚犯 B 在这 26 次机会之内找到了看守想要的牌,则两名囚犯赢得游戏,无罪释放;如果囚犯 B 翻开了 26 张牌之后,还没找到看守想要的牌,则两名囚犯输掉游戏,立即死刑。在整个游戏开始之前,两名囚犯可以商量一个策略;游戏开始后,两人就不能有任何其他形式的交流。果不其然,这又是一个关满了数学天才的监狱。两名囚犯碰头后,很快就商量出了一种必胜的策略。这种必胜的策略是什么?
算法
趣题:怎样向别人证明两个图不同构?
若干个顶点(vertex)以及某些顶点对之间的边(edge)就构成了一个图(graph)。如果图 G 和图 H 的顶点数相同,并且它们的顶点之间存在着某种对应关系,使得图 G 中的两个顶点之间有边,当且仅当图 H 中的两个对应顶点之间有边,我们就说图 G 和图 H 是同构的(isomorphism)。直观地说,两个图是同构的,意思就是它们本质上是同一个图,虽然具体的画法可能不一样。下面的两个图就是同构的。其中一种顶点对应关系是: 1 – a, 2 – c, 3 – d, 4 – b, 5 – e, 6 – g, 7 – h, 8 – f 。
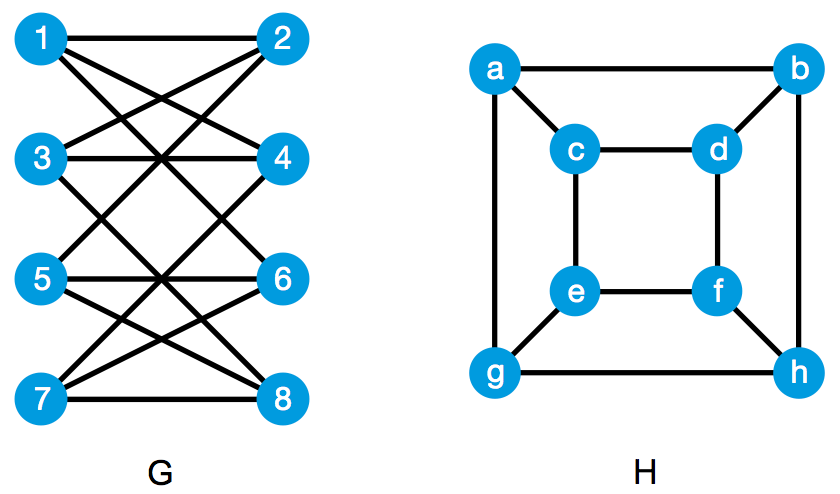
目前,人们还没有找到任何高效的算法,能迅速判断出两个图是否同构。在普通计算机上,判断两个图是否同构,这需要花费大量的时间。因此,人们经常以图的同构为例,来解释复杂度理论和现代密码学中的诸多概念。
假设你家里的计算机十分强大,能很快判断出两个图是否同构,还能在两个图确实同构的情况下,给出一种顶点对应关系。但你的同桌家里的计算机却非常弱,没法做什么大型运算。课堂上,老师向全班展示了两个很复杂的图,不妨把它们叫作图 G 和图 H 。老师布置了一个特别的选做题:判断出这两个图是否同构。每个同学都可以提交答案,答案里只需要写“是”或者“不是”即可。按时提交答案并答对者,期末考试会获得 5 分加分;按时提交答案但答错了的,期末考试成绩将会倒扣 30 分;不参与此活动的同学,期末考试既不加分也不扣分。显然,每个同学都不敢随意提交答案,除非百分之百地能保证自己获得的答案是正确的。回到家后,借助家里的超级计算机,你很快判断出了这两个图是同构的。你给你的同桌发送了信息:“我已经算出来了,这两个图是同构的。”但是,你的同桌却回复说:“你不会是骗我的吧?”你打算怎样说服他,这两个图确实是同构的呢?
趣题:用四个数学运算符号译出 EBCDIC 编码
ASCII 编码已经是非常直观了。 65 号字符就是大写字母 A , 66 号字符就是大写字母 B ,以此类推, 90 号字符就是大写字母 Z 。为了看出某个编码究竟对应字母表中的第几个字母,我们只需要用下面的函数关系即可:
f(x) = x - 64
整个函数关系极其简单,里面只包含一个数学运算符号。
当然,历史上也出现过很多非常不直观的字符编码方式。 EBCDIC 是由 IBM 提出的一种字符编码标准,它的编码方式十分古怪,可害苦了当年的那些程序员。据说,当年的程序员没有一个不痛恨 EBCDIC 的。因此, EBCDIC 也理所当然地成为了众人调侃的对象。 Wikipedia 上的 EBCDIC 页面甚至还专门有一节,讲述各种与 EBCDIC 有关的笑话。有一个经典的笑话说的就是,美国政府跑去 IBM ,想要研发一种数据加密标准,于是 EBCDIC 编码就诞生了。经典游戏 Zork 中, EBCDIC 也被用来形容艰涩难懂的文字:
一个大房间里,各式各样笨重的机器在呼呼作响,电阻烧焦了的味儿扑鼻而来。其中一面墙上有三个按钮,形状分别是圆形、三角形和正方形。自然,这些按钮上方的说明文字都是用 EBCDIC 书写的……
WOM 编码与一次写入型存储器的重复使用
计算机历史上,很多存储器的写入操作都是一次性的。 Wikipedia 的 write once read many 词条里提到了两个最经典的例子,一个是大家熟悉的 CD-R 和 DVD-R ,另一个则是更早的打孔卡片和打孔纸带。在介绍后者时,文章里说:“虽然第一次打孔之后,没有孔的区域还能继续打孔,但这么做几乎没有任何实际用处。”因此,打孔卡片和打孔纸带通常也被看成是只能写入一次的存储设备。
事实上真的是这样吗? 1982 年, Ronald Rivest 和 Adi Shamir 发表了一篇题为《怎样重复使用一次写入型存储器》(How to Reuse a “Write-Once” Memory)的论文,提出了一个很有意思的想法。大家有觉得 Ronald Rivest 和 Adi Shamir 这两个人名都很眼熟吗?没错,这两个人之前曾经和 Leonard Adleman 一道,共同建立了 RSA 公钥加密系统。其中, Ronald Rivest 就是 RSA 中的那个 R , Adi Shamir 就是 RSA 中的那个 S 。
在这篇论文的开头, Ronald Rivest 和 Adi Shamir 举了一个非常简单的例子。假设初始时存储器里的所有 bit 全是 0 。存储器的写入操作是单向的,它只能把 0 变成 1 ,却不能把 1 变成 0 。我们可以把存储器里的每 3 个 bit 分为一组,每一组都只表达 2 个 bit 的值,其中 000 和 111 都表示 00 , 100 和 011 都表示 01 , 010 和 101 都表示 10 , 001 和 110 都表示 11 。好了,假设某一天,你想用这 3 个 bit 表示出 01 ,你就可以把这 3 个 bit 从 000 改为 100 ;假设过了几天,你想再用这 3 个 bit 表示出 10 ,你就可以把这 3 个 bit 从 100 改为 101 。事实上,容易验证,对于 {00, 01, 10, 11} 中的任意两个不同的元素 a 、 b ,我们都能找到两个 3 位 01 串,使得前者表示的是 a ,后者表示的是 b ,并且前者能仅仅通过变 0 为 1 而得到后者。因此,每组里的 bit 都能使用两遍,整个存储器也就具备了“写完还能再改一次”的功能。
不可思议的是,两次表达出 {00, 01, 10, 11} 中的元素,其信息量足足有 4 个 bit ,这却只用 3 个 bit 的空间就解决了。这乍看上去似乎有些矛盾,但仔细一想你就会发现,这并没有什么问题。在写第二遍数据的时候,我们会把第一遍数据抹掉,因此总的信息量不能按照 4 个 bit 来算。利用这种技术,我们便能在 300KB 的一次写入型存储器里写入 200 KB 的内容,再把这 200KB 的内容改写成另外 200KB 的内容。这听上去似乎是神乎其神的“黑科技”,然而原理却异常简单。
趣题:用两枚硬币随机生成 1 到 n 之间的整数
为了随机地并且概率均等地生成一个 1 到 6 之间的整数,通常的做法就是抛掷一个正方体的骰子。不过,这并不是唯一的办法。如果你有一枚公正的、正反概率相同的硬币,以及一枚不公正的、正反概率之比为 1 : 2 的硬币,那么你也能概率均等地生成一个 1 到 6 之间的整数。首先抛掷那枚不公正的硬币,那么结果有 1/3 的概率是正面朝上,有 2/3 的概率是反面朝上。如果出现了正面朝上的情况,那么令 i = 1 ;如果出现了反面朝上的情况,那么就再抛掷那枚公正的硬币,掷出正面则令 i = 2 ,掷出反面则令 i = 3 。最后,再抛掷一次公正的硬币,如果正面朝上则令 j = 0 ,如果反面朝上则令 j = 3 。容易看出, i + j 的值有 1, 2, 3, 4, 5, 6 这六种可能,它们出现的概率是均等的,都是 1/6 。
有人或许会说,用硬币模拟骰子哪有那么复杂,只用一枚公正的硬币就能办到:连续抛掷三次硬币,并且规定掷出“正正正”代表数字 1 ,掷出“正正反”代表数字 2 ,“正反正”为 3 ,“正反反”为 4 ,“反正正”为 5 ,“反正反”为 6 ,掷出“反反正”和“反反反”则重来,这不就行了吗?不过,这种方法有一个局限性:它不能保证整个过程在有限步之内完成。而我们刚才的方法中,总的步骤数有一个上限:三步之内必然完成。
我们的问题是:是否对于所有的正整数 n ,都能找到两枚合适的硬币,使得借助它们便能在有限步之内概率均等地产生一个 1 到 n 之间的整数?