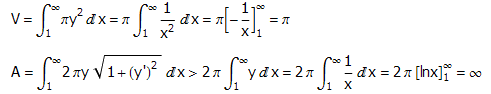1. Goldbach猜想是说,任一大于等于4的偶数一定能表示成两个质数之和。关于质数,我们还有这样一个有趣的结论:对于任何整数n>1,存在质数p满足n<=p<2n。这个结论对Goldbach猜想是很“有利”的,因为它是Goldbach猜想的一个必要条件。倘若对于某个正整数n,n和2n之间没有质数,那么偶数2n就不能表示为两个质数之和了,因为所有可以用的质数都比n小,再怎么也加不出2n来。注意,如果这个结论错了,猜想也就被推翻了;但如果这个结论对了,猜想也不一定是对的。但即使这样,我们仍然习惯性地认为,验证了推论的正确性后猜想的可靠程度也或多或少的有了些提高,换句话说猜想为真的可能性更大了。这种思维合理吗?
2. 长期以来,人们都在思考:对任一给定的平面图进行染色,要想使得有公共边的区域颜色不同,最少需要多少种颜色。四色猜想(现在已经是四色定理了)认为,只需要最多四种不同的颜色就足够了。我们可以随便画一些图进行验证,每一次检验后我们都会或多或少地更加相信结论的正确性。你可以尝试寻找下面的图1、图2和图3的合法解,检验一下猜想是否正确。验证哪一个图更有价值?你或许会这样回答:验证第一个图毫无价值,因为它显然有可行的染色方案;验证第三个图最有价值,因为它看上去最像反例,证实了它确实有解后,你会更加坚信四色猜想的正确性。1975年的4月1日,杂志Scientific American的数学专栏作家Martin Gardner宣布他找到了一个四色猜想的反例(图4)。当然,这只是一个愚人节的笑话。寻找图4的解非常困难,以致于看上去几乎是不可能的。一旦你成功找出了图4的解,对四色猜想的信任程度可就不只提高一点点了。“对猜想的某个结论进行验证,结论越是不可思议,证实以后原猜想的可靠程度就提高得越多”,这种思维是合理的吗?
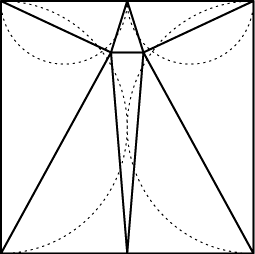
3. 你认为,是否有可能把一个直角三角形分成若干个锐角三角形?你很可能花了一节古代汉语课的时间苦思冥想,结果直角三角形没搞出来,倒是碰巧把一个正方形分成了8个锐角三角形。虽然你仍不知道一个直角三角形是否能分成若干个锐角三角形,但你找到了一个正方形的解,你会强烈地感觉到直角三角形也是有解的。这是什么原因呢?注意到,如果三角形能分的话正方形一定能分,但反过来却不一定。不过,这里面还有一些更微妙的关系:我们倾向于相信如果连直角三角形都没法分,正方形应该更没法分了。既然现在正方形已经解决了,那三角形也就快了。“B是A的结论,且没有A的B很不可靠,则证实了B可以极大地提高A的可信度”,这种思维合理吗?
4. 关于“如果他错了,那我对的概率就更大了”的思维。A、B两人被一个实际问题难住了,双方就问题中的两个变量的变化关系争执不休。A认为,函数图像画出来应该是一个开口朝上的二次函数;B则认为,函数图像应该是一个正弦函数。注意到一个有趣的事实:这两种猜测满足矛盾率,但不满足排中率。就是说,有可能A和B都错了,但是A和B不可能都对。紧接着他们发现,这个函数存在至少一个极大值,A的猜测显然是错的。虽然这并不能表明B的猜测就是对的,但我们能不能说B猜对的概率变大了?
下面的内容是G.Pólya的Mathematics and Plausible Reasoning Vol 2里的精华:用概率来分析合情推理模式。我们可以用概率知识来描述上面这些合乎情理的推测。如果你还不知道什么叫做条件概率,建议你先看一看这篇文章。
注意到P(A)*P(B|A)永远等于P(B)*P(A|B),它们都等于P(A∩B)。如果B是A的一个推论,那么有P(B|A)=1(若A为真则B必为真)。于是我们有P(A)=P(B)*P(A|B)。这里,P(A|B)有一个形象的意义:结论B的证实可以使我们对A的信任改变多少。假如P(A|B)不变,则如果等式右边的P(B)增加了,P(A)也会增加。这也就说明了我们的第一个合情推理模式:对猜想的一个结论更加信任,对猜想本身也更加信任。
这个式子还能告诉我们更多的东西。把P(B)除过去,我们有P(A|B)=P(A)/P(B),其中等式左边的P(A|B)表示的仍然是证实了B以后A为真的概率,也就是验证B结论的价值。我们很清楚地看到,P(B)处于分母的位置。那么,结论B本身为真的概率越小,证实了B后对A的影响也就越大。
注意P(B)=P(A∩B)+P(~A∩B)=P(A)*P(B|A)+P(~A)*P(B|~A),而B是A的一个结论,即P(B|A)=1。于是,等号右边变为P(A)+[1-P(A)]*P(B|~A)。利用前面的结论,我们用P(A)/P(A|B)代替等式左边的P(B),则有P(A|B)=P(A)/[P(A)+[1-P(A)]*P(B|~A)]。可以看到,如果P(B|~A)越小,则P(A|B)越大。这就是说,在没有A的前提下B成立可能性越小,证实了B之后A为真的可能性就越大。
最后,我们看一看A和B不相容的情况。此时,P(A∩B)=0,于是
P(A) = P(A∩B) + P(A∩~B)
= P(A∩~B)
= P(~B) * P(A|~B)
= [1-P(B)] * P(A|~B)
把1-P(B)除过去,就有P(A|~B)=P(A)/[1-P(B)],显然P(A|~B)是大于P(A)的,也即排除了B的猜测后A对的可能性比原来更高了。我们还可以清楚地看到,如果我们之前越相信B,则B被驳倒后A正确的可能性提高得就越多。