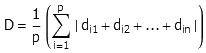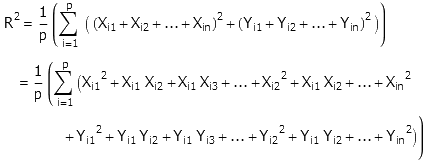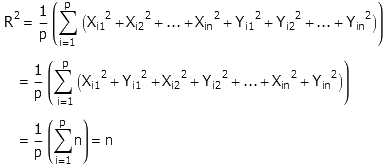摘录几道题目。
计算1·2^2 + 2·3^2 + 3·4^2 + … + 19·20^2
原式 = (1^3 + 2^3 + … + 20^3) – (1^2 + 2^2 + … + 20^2) = 44100 – 2870 = 41230
求2^x = 3^y – 1的所有正整数解
x=1时(1,1)是一个解;当x>1时,方程模4后左边永远等于0,右边则是(-1)^y – 1,可知y为偶数。令y=2z,那么有2^x = (3^z – 1)(3^z + 1),这就要求3^z-1和3^z+1都是2的幂;但它们只相差2,因此它们只有可能是2和4,于是z=1,即原方程的另一个解为(3,2)。
圆周上有2008个点。选择两个点连成一条线,再选另外两点连一条线,这两条线段相交的概率为多少?
给定四个点,在三种连接方案中恰有一种会发生相交。取遍所有C(2008,4)种组合,相交的总情况数总是占了1/3,因此所求的概率就是1/3。