一个正整数n的阶乘就是前n个正整数的乘积,我们通常需要n-1次乘法操作来算出精确的值。不像等差数列求和、a的n次幂之类的东西,目前求阶乘还没有什么巨牛无比的高效算法,我们所能做的仅仅是做一些小的优化。
更少的乘法运算次数?
在高精度运算中,乘法计算的速度远远慢于加减法,因此我们有必要减少乘法运算的次数。下面我将做一个非常简单的变换,使得计算阶乘只需要n/2次乘法。继续看下去之前,你能自己想到这个算法来吗?
我们可以把一个数的阶乘转换为若干个平方差的积。例如,假如我想求9!,我可以把前9个正整数的乘积写成这个样子:
1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9
= (5-4) * (5-3) * (5-2) * (5-1) * 5 * (5+1) * (5+2) * (5+3) * (5+4)
= (5-1) * (5+1) * (5-2) * (5+2) * (5-3) * (5+3) * (5-4) * (5+4) * 5
= (5^2 – 1^2) * (5^2 – 2^2) * (5^2 – 3^2) * (5^2 – 4^2) * 5
注意到一个有趣的事实:上面的四个平方差算出来分别是24, 21, 16, 9,它们之间的差正好是连续的奇数(因为n^2等于前n个正奇数的和)。因此,我们可以用初始数(n/2)^2不断减去一个个的正奇数,求出所有n/2个平方差,再用n/2次乘法把它们乘起来。这种算法实现起来非常简单,并且(当n不大时)同样只需要单精度乘高精度,但需要的乘法次数大大减少了。假设我们已经有了一个高精度类,求n!只需要下面几句话:long h=n/2, q=h*h;
long r = (n&1)==1 ? 2*q*n : 2*q;
f = LargeInteger.create(r);
for(int d=1; d<n-2; d+=2)
f = f.multiply(q-=d);
更少的总运算次数?
尽量提取阶乘中的因子2,我们可以得到另一种阶乘运算的优化方法。这很可能是不需要分解质因数的阶乘算法中最快的一种。
假如我们需要计算20!,我们可以把20拆成若干组正奇数的乘积:
1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 * 17 * 18 * 19 * 20
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 2 * 4 * 6 * 8 * 10 * 12 * 14 * 16 * 18 * 20
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10 * 2^10
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 1 * 3 * 5 * 7 * 9 * 2 * 4 * 6 * 8 * 10 * 2^10
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 1 * 3 * 5 * 7 * 9 * 1 * 2 * 3 * 4 * 5 * 2^15
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 1 * 3 * 5 * 7 * 9 * 1 * 3 * 5 * 2 * 4 * 2^15
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 1 * 3 * 5 * 7 * 9 * 1 * 3 * 5 * 1 * 2 * 2^17
= 1 * 3 * 5 * 7 * 9 * 11 * 13 * 15 * 17 * 19 * 1 * 3 * 5 * 7 * 9 * 1 * 3 * 5 * 1 * 2^18
只需要一次累乘就可以求到每一组奇数的乘积,最后再花费log(n)次乘法把它们全部乘起来。最后的那个2^18也可以二分计算出来。真正的代码还有很多细节上的优化,另外还借用了递归使得操作变得更加简便。你可以在本文最后附的那个链接里去找Split-Recursive算法。
还能再快一点么?
继续扩展上面的算法,我们可以想到,如果把每个数的质因数都分解出来,并且统计每种质因子有多少个,我们就可以多次使用二分求幂,再把它们的结果乘起来。注意这里并不是真的要老老实实地去分解每个数的质因子。对于每个质数x,我们可以很快算出前n个正整数一共包含有多少个质因子x(记得如何求n!末尾有多少个0么)。这种算法的效率相当高,已经能够满足大多数人的需要了。
另一种诡异的阶乘算法:
这个算法可能是所有有名字的阶乘算法中最慢的一个了(Additive Moessner算法),它对一个数列进行重复的累加操作,一次次地计算前缀和,总共将花费O(n^3)次加法操作。但是,令人费解的是,这个简单的程序为什么可以输出前n个正整数的阶乘呢?a[0]:=1;
for i:=1 to n do
begin
a[i]:=0;
for j:=n downto 1 do
begin
for k:=1 to j do
a[k]:=a[k]+a[k-1]
write(a[i],' ');
end;
end;
我在网上搜索相关的东西时找到了另一个有趣的东西。对一个初始时全为1的数列反复进行这两个操作:累加求前缀和,然后以1,2,3,…的间隔划掉其中一部分数(即划去所有位置编号为三角形数的数)形成新的序列。类似的数列操作方法最先由Alfred Moessner提出的,我们这里不妨把它叫做Moessner数列。你会发现,第n轮操作开始前,数列的第一个数恰好是n! 。看看下面的例子吧:
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 …
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 …
x 2 x 4 5 x 7 8 9 x 11 12 13 14 x …
2 4 5 7 8 9 11 12 13 14 …
2 6 11 18 26 35 46 58 71 85 …
x 6 x 18 26 x 46 58 71 x …
6 18 26 46 58 71 …
6 24 50 96 154 225 …
x 24 x 96 154 x …
24 96 154 …
24 120 274 …
x 120 x …
120 …
…..
当然,发现前面O(n^3)的程序和这个Moessner数列的关联时我很是吃了一惊:在前面的程序里,如果你输出每一次i循环末所得到的数列,你会发现输出的这些数正好就是后面这个问题里被我们划掉的数,而它们其实就是第一类Stirling数!
这到底是为什么呢?是什么东西把阶乘、第一类Stirling数、Moessner数列和那个O(n^3)的程序联系在一起的呢?昨天,我想这个问题想了一天,最后终于想通了。如果把Moessner数列排列成这个样子,一切就恍然大悟了:
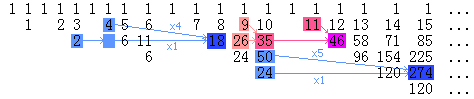
仔细观察上图,我们会发现:
1. 按照Moessner数列的定义,每个数都应该等于它左边的数和左上角的数的和(这个“左边”可以跳过若干空格)。例如,35 = 9 + 26,46 = 11 + 35。排成一系列三角形后,每个三角形最右边一列的数就是被划去的数,它永远不能参与它下面的那些行的运算。
2. 设a[n,i,j]表示左起第n个三角形阵列中的第i行右起第j列上的数,则a[n,i,j]=a[n-1,i-1,j]*n + a[n-1,i,j],例如274=50*5+24。如果递推时遇到空白位置而它左边隔若干空格的地方还有数的话,则需要用左边的数来补,例如18=4*4+2。对于每个三角形的最后一列来说,这个性质实际上就是第一类Stirling数的递推关系,因此Moessner数列中才会出现第一类Stirling数。
3. 在第一类Stirling数中,s(n,1)=n! ,也即左起第n个三角形最底端的那个数等于n!。从上面的第二个性质来看,这也是显然的。
4. O(n^3)的算法实际上就是在绘制上面这个图。每一次j循环末,我们得到
的序列是第i个三角形中每一行左起第j个数组成的序列。例如,计算第5个三角形内的数时,程序首先累加出1, 11, 46, 96, 120, 120,这样便算出了a[5]=120,数列的前5个数再次累加即得到1, 12, 58, 154, 274,由此算出a[4]=274。
第二个性质可以利用第一个性质进行数学归纳法证明,证明很简单,我就不多说了。现在我尽可能少写一些繁琐的细节,节约一些时间用来复习古代汉语。
做人要厚道,
转贴请注明出处。
查看更多:
http://www.luschny.de/math/factorial/FastFactorialFunctions.htm
http://www.luschny.de/math/factorial/index.html <—- 巨牛,20多种阶乘算法的代码!